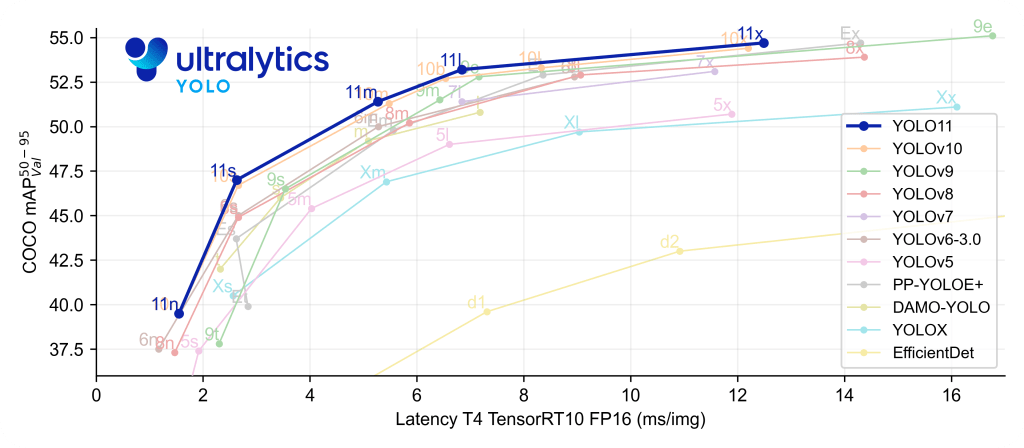
The You Only Look Once (YOLO) series is popular and versatile in 2D computer vision tasks like object detection, segmentation, or pose estimation. Its good performance and high efficiency allow the YOLO series to become the state-of-the-art real-time model. As shown in the graph below, the latest YOLO11 achieves a mean average precision of 54.7 in the object detection task within a real-time setting.
Despite the many improvements been made throughout the development of the YOLO-series, the original idea of YOLO is innovative and remarkable. In this article, I want to revisit the original YOLO, which is a unified framework proposed in 2016 [1], and explore the idea behind the original YOLO.
Unified Detection Framework
Before YOLO was proposed, the object detection task was often viewed as a 2-steps task, where the bounding boxes are first proposed by a deep-learning model, followed by a classifier to classify the object in the bounding boxes. One success method is the R-CNN series method. This 2-step model is often slow to compute and hard to optimize. To overcome this problem, the YOLO proposed a unified detection framework that solves the object detection problem using a single deep neural network. The 1-step YOLO is easier to optimize and more efficient compared to the 2-step methods.
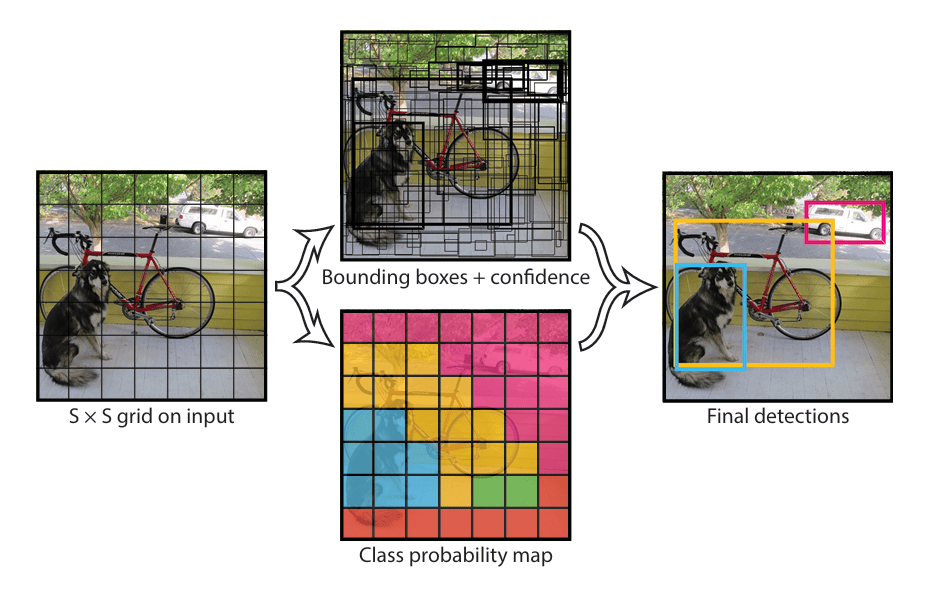
The methodologies of the YOLO are divided into 4 steps: grid-based input segmentation, bounding boxes and confidence prediction, conditional class probability map prediction, and non-max suppression (NMS) bounding boxes integration.
- Divide the image into an S*S grid
First, the input image will be divided into an S*S grid, where S is set to 7 in the original paper.
- Each grid cell predict B bounding box [x,y,w,h,c]
Each grid cell is responsible for generating B bounding boxes, where each bounding box is composed of 5 parameters: the center(x, y), width, height, and the confidence of the predicted bounding box. The B is set to 2 in the original paper.
- A conditional class probability map is predicted
Moreover, a conditional class probability map is predicted, where each grid cell is assigned a class probability.
- Non-max suppression
Lastly, the bounding boxes and the class probability map are integrated using non-max suppression. The NMS algorithm can remove duplicate bounding boxes and retain the one with the largest confidence above the threshold.
YOLO’s backbone
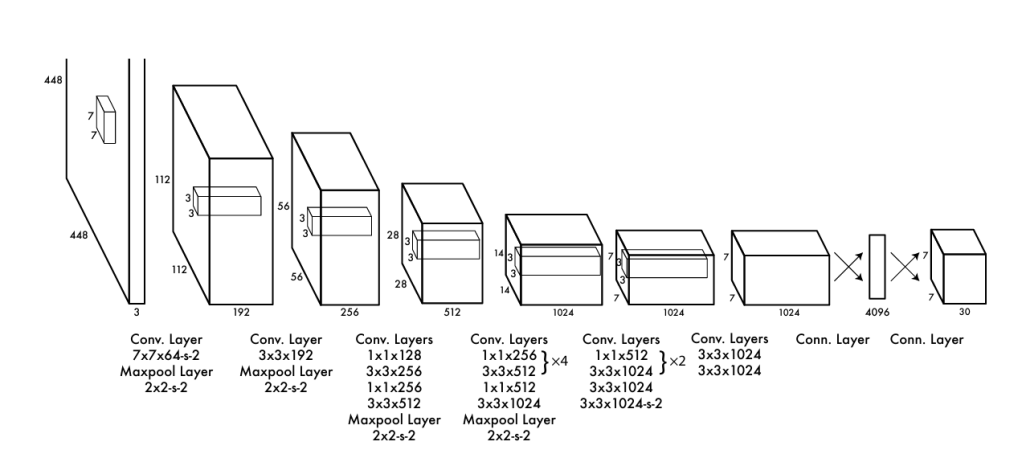
The backbone of the YOLO is inspired by the GoogLeNet [3], which composed of 24 convolutional layers, followed by 2 fully connected layers. The output consists of 7*7*30 tensors, where 7*7 is the S*S grids, and the 30 represents the PASCAL dataset classes (20) and the bounding box prediction (each grid predicts 2 bounding boxes, and each bounding box is composed of 5 parameters).
Training Loss
The training loss of the YOLO is composed of the localization loss and the Classification loss.
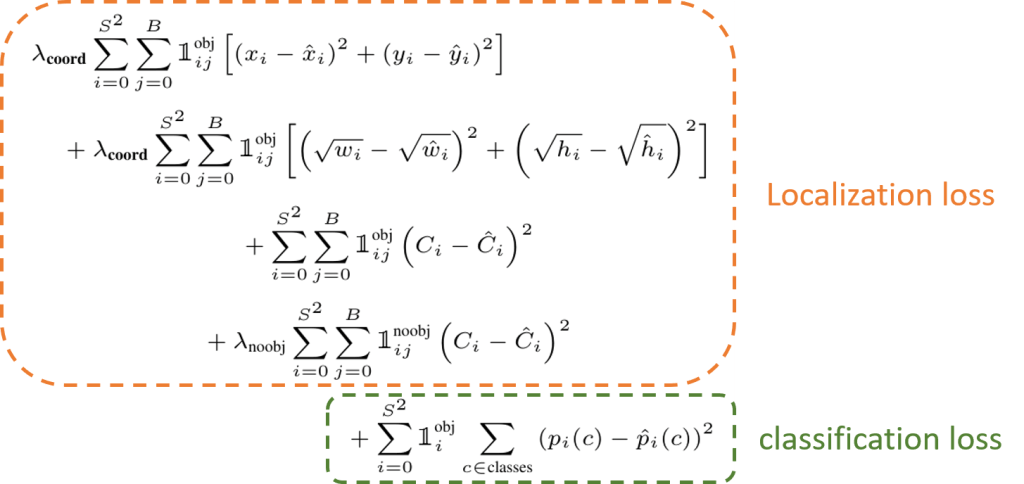
The first 4 terms of the equation correspond to the bounding box loss, where they are taking the sum-squared error between predicted bounding boxes and the ground truth bounding boxes, as it is easier to optimize. The last terms represent the class loss, where p is the output probabilities of each class. The YOLO takes lambda_coord = 5 and lambda_noobj = 0.5. The objective is to decrease the effects of the empty grid. As there are often more ‘no-object grids’ than ‘object grids’, without a balancing factor, the confidence error of the ‘no-object grid’ is too influential and will affect the training. The YOLO is first pre-trained on the ImageNet 1000-class competition dataset, then fine-tuned with the objective dataset.
Limitation
There are several limitations to this raw-YOLO, like struggles in small object detection and incorrect localization. The YOLO backbone uses quite coarse features (due to multiple times of down sampling layers) to perform the detection, which faces an obstacle in small object detection. Then, the loss function, which treats the large objects and small objects equally, may damage the performance of the localization of the small objects. (Small localization error in a big object may be OK, but bad if the object is small).
Conclusion
In conclusion, this article reviews the origin of YOLO and explains the innovation of this unified detection framework. Since then, there have been more and more developments and improvements to the YOLO series models.
Thank you for reading! Do you have any articles that you want to read but no times too? Leave the articles in comment and I will try to help you up!

Leave a comment