The Key point detection and feature extraction are fundamental techniques in many computer vision downstream tasks, like camera calibration, homography estimation, structure-from-motion, and visual-SLAM. The task is to extract and describe the key points in each image.
The traditional key point detectors and descriptors like ORB, FAST, and SIFT can achieve good performance in the task. Meanwhile, these descriptors often encounter obstacles when dealing with ill-pose images, like blurry images, low lighting conditions, or weak-texture surfaces. In the deep-learning era, the deep neural network is proven to extract a more distinctive feature descriptor, which potentially cracking the ill-pose image feature extraction (DeTone, 2018).
In this article, let’s dive into a benchmark learning-based key point detector and descriptor, SuperPoint.
How to prepare a training dataset?
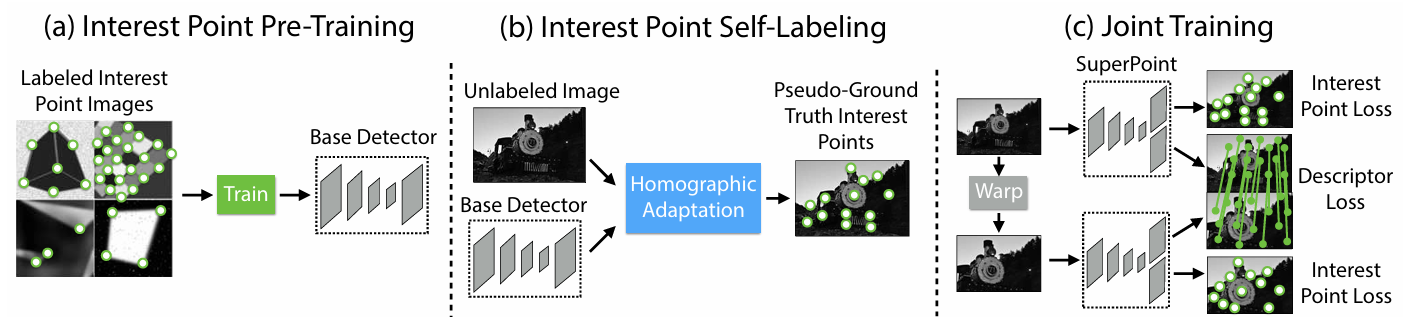
Training a neural network requires a dataset. However, unlike the other tasks like object detection or segmentation, there are no subjective definitions of the key point in an image. One can say the key point is the corner of the structure or building; however, in an outdoor scene, the lack of clarification in the definition brings difficulties in obtaining a training dataset. To deal with this problem, the SuperPoint proposed using a Base Detector trained on the synthetic dataset and the Homographic Adaptation to generate a ground truth key point dataset.
Base detector training with synthetic dataset
A base detector (MagicPoint) is trained with the synthetic dataset to perform the key point detection task. Then, the MagicPoint will act as a pre-trained model to generate the ground truth for the SuperPoint training. The large-scale synthetic dataset consists of simple 2D geometry, where their junction are annotated as the key point position. The synthesis is done automatically; some examples are shown in the figure below.

Despite training on the synthetic dataset, the MagicPoint can perform well in real-world images. It shows high repeatability across different real-world images, even under some noise.
Homographic adaptation for SuperPoint training data annotation
The consecutive step to obtain the real-world dataset is to use the MagicPoint as a base detector and perform the homographic adaptation.
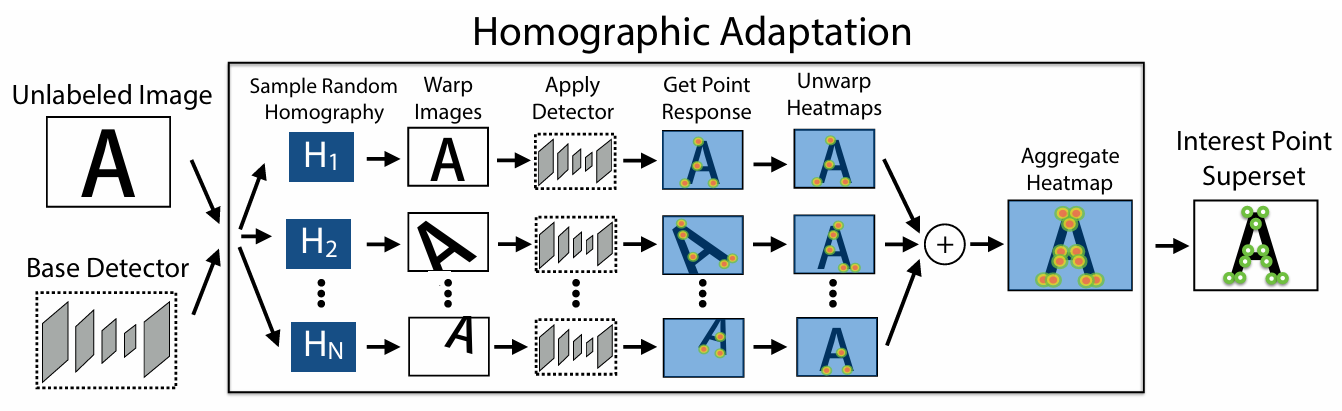
Homography is a 2D perspective transformation applied to an image to get an image from a new viewpoint. In the homographic adaptation step, random homographies are first applied to the input unlabeled image to obtain multi-viewpoint images. Then, the MagicPoint is used to perform key point detection on each wrap image. These detected key points can then be concatenated to obtain the final key point superset. Interestingly, the MagicPoint detects different keypoints from different homographic images, which made the concatenation meaningful. Overall, the author used a pre-trained base model and the homographic adaptation strategy to obtain a pseudo ground truth keypoint training set.
Architecture of SuperPoint
The architecture of SuperPoint is rather simple, it inherits a VGG-style convolutional neural network as encoder to extract the image features. The encoder consists of layers like convolution layers, dropout layers, and pooling layers. The encode feature is then connected to an interest point decoder head and a descriptor decoder head. Do note that both decoder heads are designed as non-trainable heads to decrease the computational cost.

Training Loss
Two losses are used to train the SuperPoint: the interest point detector loss and the descriptor loss. The interest point detector loss is a cross-entropy loss over each pixel, which basically do classification loss over all pixels. The descriptor loss is a hinge loss, which is often used in the descriptor learning. The hinge loss will try to pull the positive matches descriptor’s distance closer and push the negative matches descriptor’s distance further. These losses are combined with a proportion as a hyper-parameter.
Evaluation and results
Key Point Repeatability
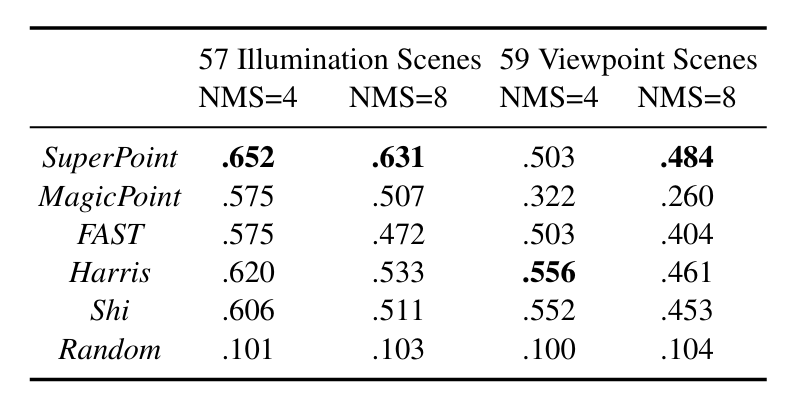
The SuperPoint is benchmarking using the HPatches dataset (Balntas, 2017). According to the experiment results, its repeatability in different illumination and viewpoint scenes outperformed the other detectors, like FAST, Harris, and Shi. It shows the consistency of SuperPoint’s key point detection ability.
Result of Homography Estimation
The author also applied the SuperPoint in a homography estimation task (HPatches Homography Estimation) to evaluate its performance.
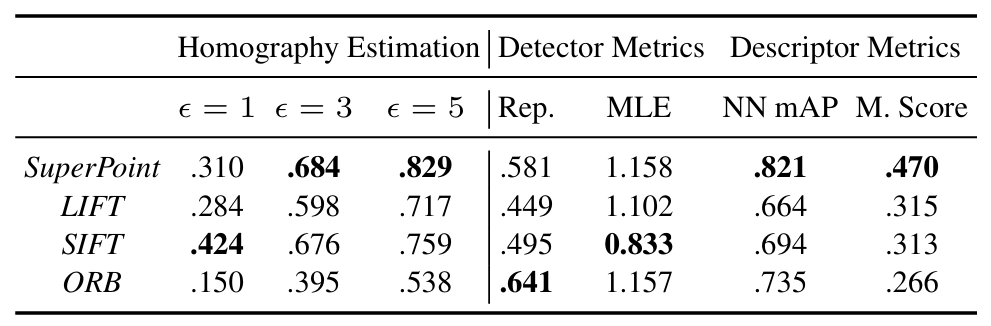
The SuperPoint outperformed the LIFT and ORB in most of the conditions and is comparable with the SIFT descriptor (most used traditional descriptor), with higher score in the descriptor metrics.
Conclusion
In conclusion, the SuperPoint is designed in this work, leveraging the ability of the deep learning into feature extraction. The work contains several highlights.
- The SuperPoint jointly extracts the key point and the descriptor within one forward pass, which is efficient.
- It adopts the neural network’s ability to extract a distinctive descriptor, which surpluses traditional descriptors in metrics.
- It developed an automatic training data labeling method (Homographic adaptation) to achieve a self-supervised model training pipeline.
This is a work from 2018, which is quite a long time ago. Another work, SuperGlue, which was developed by the same lab, was released in 2020, focusing on improving the descriptor matching network (instead of brute force matching). Please check out this paper if you are interested.
Thanks for reading, I cannot cover every single detail of the article, and I encourage you to read through the original research paper by yourself, and definitely you will find something new. Please leave me a comment for any suggestion.
Reference
- DeTone, D., Malisiewicz, T., & Rabinovich, A. (2018). Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops (pp. 224-236).
- Balntas, V., Lenc, K., Vedaldi, A., & Mikolajczyk, K. (2017). HPatches: A benchmark and evaluation of handcrafted and learned local descriptors. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5173-5182).
- Sarlin, P. E., DeTone, D., Malisiewicz, T., & Rabinovich, A. (2020). Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4938-4947).

Leave a comment