FoundationStereo by NVIDIA posted a State-of-the-art stereo model that outperformed all existing models. Let’s take a look at how this model performs.
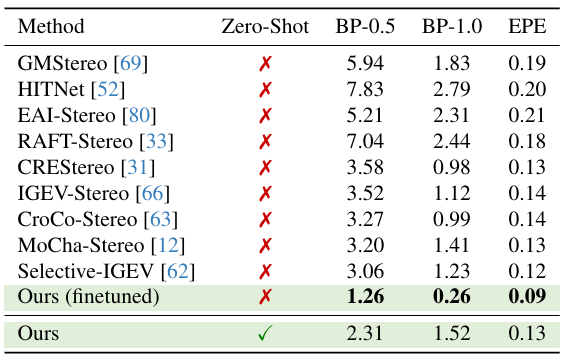
Even with zero-shot inference (no fine-tuning with the dataset), the FoundationStereo outperformed all existing stereo models. More results and cool visualizations can be seen on the project website.
In this article, I will introduce the objective of the stereo problem, why is it challenging? How does FoundationStereo solve it? and what are my opinions?
Problem defination
Stereo depth estimation is an important problem in the computer vision community. The problem statement is as follows:
Given a left image and a right image, can I recover the depth of each pixel (definitely YES), and how?
traditional method
A traditional way to solve this problem is through multi-view-stereo (MVS), where the method analogs how the human eyes function, and uses the parallax between two calibrated cameras to obtain the depth, we will have a blog write about this in detail. However, the traditional method highly relies on feature matching between images to calibrate them, therefore often facing challenges in the textureless surface and poor lighting conditions.
deep learning method
As the deep learning vision develops, many researchers proposed using the model to directly predict a depth map to solve the stereo problem. That is, how about we just skip all those feature matching and camera position estimation steps, and use a deep learning model to directly predict the depth of each pixel? Even some just use a single image (mono-depth). Some examples are Depth Everything 2, DepthPro, RAFT-Stereo [4,5,2]. However, these models often faced these challenges: poor generalize ability, sim-to-real discrepancy, and instable performance in hard cases.
Methodology
To overcome these challenges, FoundationStereo proposes 5 keys in the structure.
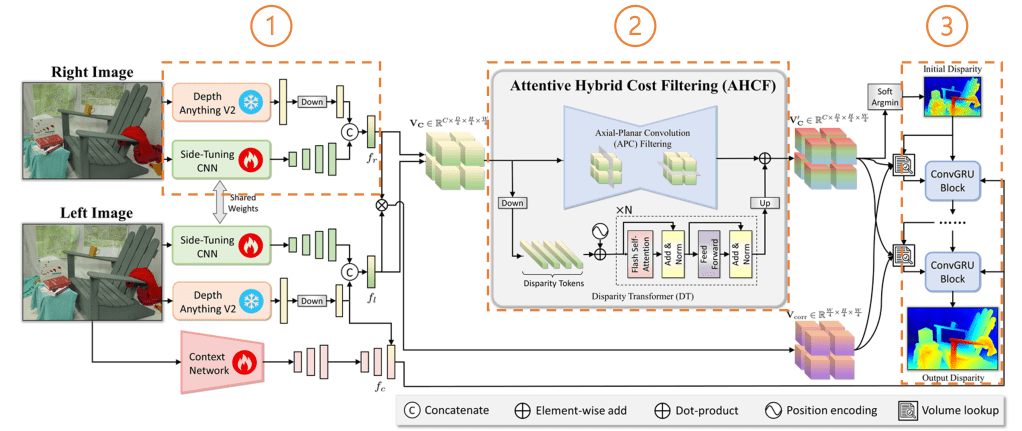
1. Use clues from mono-depth estimation to close the gap of sim-to-real
FoundationStereo adapts the mono-depth estimation model into the framework to overcome the sim-to-real problem. By downscaling the mono-depth model’s feature before the final output using a CNN, the feature size can be matched and concatenated with a side-tuning CNN which is applied to the images directly. These concatenated features leverage both simulation training data and the real-world mono-depth model’s feature, which greatly improves depth prediction. More ablation studies on the concatenation frameworks can be found in section 4.5 of the paper.
2. Attentive Hybrid Cost Filtering
After obtaining the hybrid features from the original images and the monocular model, the features are passed through an Axial-Planar Convolution (APC) filtering and a Disparity Transformer (DT) structure respectively. These structures aggregate the features along spatial and disparity dimensions over the 4D hybrid cost volume. More detail can be checked in the paper, but you can think of it as a structure to extract and aggregate those features effectively. After this process, an initial disparity map is predicted.
3. Iterative refinement
The FoundationStereo applied a coarse-to-fine iterative refinement strategy on the final prediction. The strategy uses the GRU to prevent local minima and accelerate convergence. The detailed updating rule can be found in Section 3.3. More detail about the iterative refinement technique can be checked on RAFT-stereo [2].
4. Training loss
The training loss used in the training of FoundationStereo is the smooth L1 loss between the ground truth disparity map and the predicted depth, with an iterative refinement loss term (from RAFT-Stereo) additionally to supervise the refinement process.
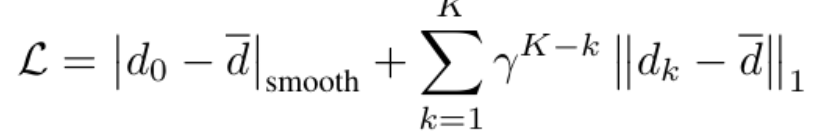
5. Synthetic FoundationStereo Dataset (FSD) & self-data curation
To obtain more training data and include more hard cases, like low texture, occlusion, and bad lighting conditions, FoundationStereo used NVIDIA Omniverse to create a large-scale synthetic training dataset. The dataset used techniques like domain randomization [3], abundant texturing, and path-tracing rendering to augment and synthesize more realistic indoor and outdoor stereo pairs. Some images are shown as below.

Moreover, they incorporate a self-curation rule to eliminate the ambiguous stereo-pair. By training the FoundationStereo with the initial FSD, then the stereo pair which have a larger error is eliminated and re-generated. These processes update both the FSD and FoundationStereo model into a better dataset and model.
Through this framework, FoundationStereo becomes the SOTA zero-shot stereo model, I want to share these insights and observations.
Discussion
1. Leveraging both mono-depth and stereo-vision
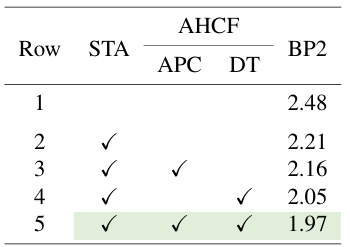
By integrating the mono-depth feature and stereo feature, the model’s performance increased significantly. This adaptation also provides the model with a general ability to perform well on unseen datasets (zero-shot adaptation). According to the ablation study, by adding the STA module, the BP2 metric improved from 2.48 to 2.21. The mono-depth model provides more real-world understanding to improve the stereo model.
2. Improvement in the hard cases
The FoundationStereo can perform well in the hard cases, like occlusion or plain-texture. Some examples are shown below.

Most cases contained low-texture surfaces and may have failed using the traditional MVS method or other deep-learning models.
3. How to perform multi-view stereo?
The FoundationStereo takes 2 input images and predicts a disparity map. However, without the process of feature matching, how can the model be integrated into a multi-view-stereo pipeline? In other words, if we provide more images, can the depth estimation be further refined?
Conclusion
In conclusion, the FoundationStereo becomes the SOTA in the stereo task, and its zero-shot ability is amazing. The 5 keys to understanding this model include the integration of monocular and stereo models, the Attentive Hybrid Cost Filtering, the iterative refinement process, the smooth L1 training loss, and the large-scale synthetic dataset.
I hope this summarize article help you understand FoundationStereo. If the article helps, please like and share to your friends! Please leave a comment for any further discussions!
Reference
- Wen, B., Trepte, M., Aribido, J., Kautz, J., Gallo, O., & Birchfield, S. (2025). FoundationStereo: Zero-Shot Stereo Matching. arXiv preprint arXiv:2501.09898.
- Lipson, L., Teed, Z., & Deng, J. (2021, December). Raft-stereo: Multilevel recurrent field transforms for stereo matching. In 2021 International Conference on 3D Vision (3DV) (pp. 218-227). IEEE.
- Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W., & Abbeel, P. (2017, September). Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) (pp. 23-30). IEEE.
- Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., & Zhao, H. (2024). Depth Anything V2. arXiv preprint arXiv:2406.09414.
- Bochkovskii, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S. R., & Koltun, V. (2024). Depth pro: Sharp monocular metric depth in less than a second. arXiv preprint arXiv:2410.02073.

Leave a comment